

Academic research has an honesty problem
Academic research has an honesty problem
The tale of a top professor at Harvard, academic dishonesty and the shocking truths it reveals about academia

Dishonesty amongst honesty researchers
I bet you’ve heard of Dan Ariely. If you haven’t, I urge you to read his books Predictably Irrational and The Honest Truth about Dishonesty. Ariely is a big name in psychology and behavioral economics; he serves as a professor of psychology and behavioral economics at Duke University, he has multiple bestsellers and has advised/founded a lot of companies in the space.
Francesca Gino is a behavioral scientist and a professor at Harvard University. Gino is known for her research on rule-breaking, which she discusses in her book, Rebel Talent (another bestseller).
Both of these people have been accused of academic dishonesty, data manipulation and, as of writing, Gino is on administrative leave from Harvard. The paper that these influential individuals have collaborated on, ironically about dishonesty, has been retracted and heavily scrutinized by the academic community. Mind you that Gino has published her work on peer reviewed journals and her research has been cited hundreds of times. As of writing, a total of 4 of Gino’s research papers (almost all of her life’s work) have been found to be based on manipulated data.
Sherlock Holmes if he was a statistician
This article isn’t just about academic dishonesty and the flaws of the peer review process; I wanted to focus on some excellent detective work done by 3 amazing researchers: Uri Simonsohn, Leif Nelson and Joe Simmons. Our 3 Sherlocks have an insightful blog, Data Colada, which details all of their findings on Gino’s work and how they helped uncover this mystery. I provide a summary below but I urge you to read their blog as well.
Uri, Leif and Joe’s first article digs deeper into Gino and Ariely’s collaborative paper - Signing at the beginning makes ethics salient and decreases dishonest self-reports in comparison to signing at the end. The paper’s three studies show that people will lie less when they sign an honesty pledge (“I promise I won’t cheat”) at the top of a form rather than the bottom.
I won’t go much into the study but the participants had a financial incentive to solve multiple puzzles correctly. The catch was that the participants believed only they would know how many they got correct. So they could lie about their scores. this was like a self graded test. In reality, the researchers knew if the participants lied about their scores.
The participants were separated into two groups. The only difference between groups was that some people would have to sign an honesty pledge at the start of the page and others at the bottom. Signing at the top vs. the bottom lowered the share of people over-reporting their puzzle performance from 79% to 37% and lowered the average amount of over-reporting from 3.94 puzzles to 0.77 puzzles. These were highly statistically significant at p values less than 1% (p < .001% for one of these to be exact which means you can be almost certain that there’s an effect).
These startling finds are very rare in academic research. Below is the excel sheet which contained the responses the researchers got. Notice the first column, P# or participant ID, which highlights inconsistencies in sorting (highlighted in yellow).

Some IDs have been duplicated, while others are out of place. The sorting should be by P# (participant ID) and Cond (the group they were in - bottom signing vs top) but this wasn’t followed for these few participants. This seems strange - why would the researchers sort some participants and not others?
If these rows were assumed to be tampered with, we would expect the removal of these participants to make the results weaker. That’s exactly what happens.

The tampered data are all at the extremes (expenses claimed was another part of the experiment - there was financial incentive to claim higher expenses) and enforce that sign-top leads to less dishonesty (and thus lower expenses claimed) vs sign-bottom.
Our heroes Uri, Leif and Joe go full Batman mode and analyze the excel file itself - Excel files are a combination of multiple files, one of which is called calcChain.xml (if you want to test this, unzip xlsx files via software like 7zip). calcChain tells Excel about the sequence of operations it must do to complete a formula.
Importantly, calcChain will have the order in which formulas were initially entered into the spreadsheet. It will indicate to first solve x, then y, and so on. Critically, when a cell is moved, its order of calculation is not.

Using this fact and the sorting of the ids, our detectives easily found out the data was tampered with.
“My class year is Harvard”
The second article on Data Colada by our 3 sleuths analyses the data from The Moral Virtue of Authenticity: How Inauthenticity Produces Feelings of Immorality and Impurity published on Psychological Science by Gino, Kouchaki, & Galinsky. In this paper, Gino and co presented five studies suggesting that being inauthentic (or lying) leads people to feel more impure.
It’s an interesting study, kind of bizarre as well. Harvard students were asked to express an opinion about a Harvard campus issue. They were then asked to write an essay about that issue that either argued in favor of their belief or against it. After writing the essay, participants rated how desirable they found five cleansing products to be. The authors predicted that writing against your belief would make participants feel dirty/impure, which would increase their desire for cleansing products.
As expected, the effect sizes were crazy and the result was very statistically significant - being inauthentic would increase your desire for cleaning products.
Participants were also asked to provide demographic information before the study:

Notice how badly worded the last question is. “Year in School” can be answered so many ways - sophomore, Year 2, graduation year, 2019? However, you’d never expect students to write “Harvard” as their year in school.

This is where the title of our 3 investigators’ article comes from - “My class year is harvard”. And you thought academics didn’t have a sense of humor.
If these rows were tampered with, we would expect they would help to confirm the authors’ hypothesis. As expected, they’re on the extreme ends of the analysis (barring one random datapoint - maybe that student actually did write Harvard as their class year).

Evil Genius: How dishonesty can lead to greater creativity fame
This time our 3 Nancy Drews (I’m running out of detective names) look at Gino & Wiltermuth’s study titled Evil Genius? How Dishonesty Can Lead to Greater Creativity. Participants were randomly given the incentive and the opportunity to cheat. They were then asked to generate as many creative uses for a newspaper as possible within 1 min, a common test for creativity.
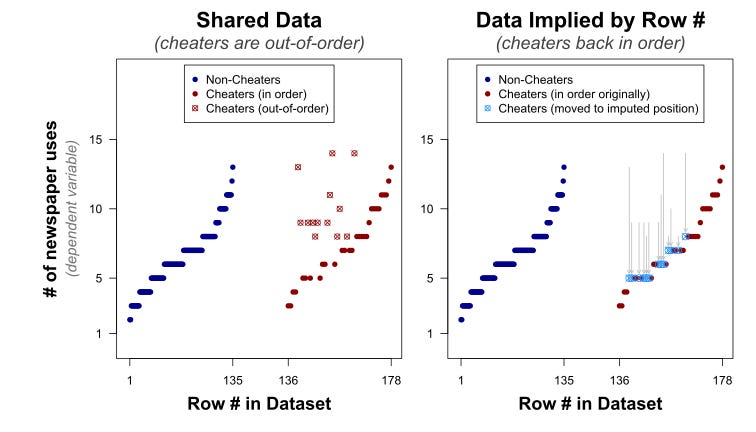
The data here is another case of sorting revealing inconsistencies. Notice how the data is sorted by the cheated column, followed by the number of responses (number of uses of the newspaper). Non cheaters have a very clean sorting (not shown below but you can find it in their blog) but cheaters have a random sorting as shown below.

These out of place response numbers (highlighted in yellow) can be imputed to be higher or lower - so Cum_ID 36 can be imputed to be 4 responses (lower imputation) or 5 responses (higher imputation). As can be seen below, imputing the values shows two similar distributions; all the tampered values are clearly out of place of the original distribution of newspaper uses. Our investigators do some more number crunching to prove that the two distributions are the same1.
Coup de grâce
The final nail in the coffin is on Gino, Kouchaki, & Casciaro’s study: Why Connect? Moral Consequences of Networking with a Promotion or Prevention Focus. The authors propose that being in a particular mindset affects how people feel about networking - "promotion focus" and "prevention focus" mindsets were investigated. Promotion focus involves thinking about what one wants to do, while prevention focus involves thinking about what one should do. The authors predicted that people would feel worse about networking when in a "prevention focused" mindset.

This experiment is complicated and we’ll only look at the important bits that our Hercule Poirots found out (that’s the last famous detective I know). The study induced the two mindsets on the user and asked them to rate how the event made them feel and also use words to describe it:

Uri, Leif and Joe guessed that the scores may be manipulated but the authors might have been lazy to change the words. And that’s exactly what happened.


Our detectives surmise that if the researcher faked the ratings but not the words – then the authors’ effect should go away when you just analyze the words. But it not only goes away; it for some reason reverses. Most of this could be random chance, the 3 conclude. Thanks to these articles and the work of many other academics, Gino’s and Ariely’s work is being looked into, some of Gino’s work has been retracted and she has been placed on administrative leave by Harvard.
A lesson in honesty, duplicity and status
A lot of this highlights that there exists a real problem in academia in regards to honesty and incentivisation. The reason for duplicity is obvious - if you report large effects and provide startling conclusions, then you’re expected to be published more often, become more famous and make more money. The incentive structure is flawed and incentivizes people to falsify or exaggerate research. This is pervasive in many research areas, one of the most egregious being medical research.
This is sad because academia is notoriously underpaid compared to comparable careers in industry - a lot of academics will produce groundbreaking research that some large corporate will profit heavily off of and the researcher barely gets anything (except for recognition). How many academics will produce groundbreaking research in their lifetime? How much groundbreaking research can be produced continuously? Should academics be incentivized to produce research regardless of surprisingly positive results? These are all questions that the community and academic institutions will need to answer to prevent such gross cases of dishonest research.
Another interesting point is that if you’re already a person in a position of power e.g., you teach at Harvard, you will be less scrutinized when you publish papers. Think about it, some of these startling results should have been big red flags when they were published and reviewed. I don’t want to take anything from our investigators (and this might be hindsight) but the indicators of data manipulation were relatively easy to spot. The data manipulation work was amateur and left an easy trail. I suspect (but cannot confirm) that the original peer reviewers didn’t do their job properly because Gino and co were established individuals and assumed to be reliable because of that.
This shouldn’t be the status quo and I hope that this shakeup helps to promote better research and better incentive structures.
A very well narrated video from one of my favorite content creators, Veritasium, about published research and how most of it might be wrong:
Pete Judo’s video on the scandal I described in this article:
They look at how only the removal of these 13 tampered values produce similar distributions; removal of any other combination of 13 values would not produce similar distributions so these 13 are very clearly tampered with.